Overview
If you want to read/write shp files in Python you are probably going to use pyshp (or maybe Fiona).
I tried to find a python complement for pyshp library in pypi that could make queries on the database file .dbf.
Given the Spanish census section shapefile (INE Cartografía digitalizada) we can visualize it with Mapshaper:
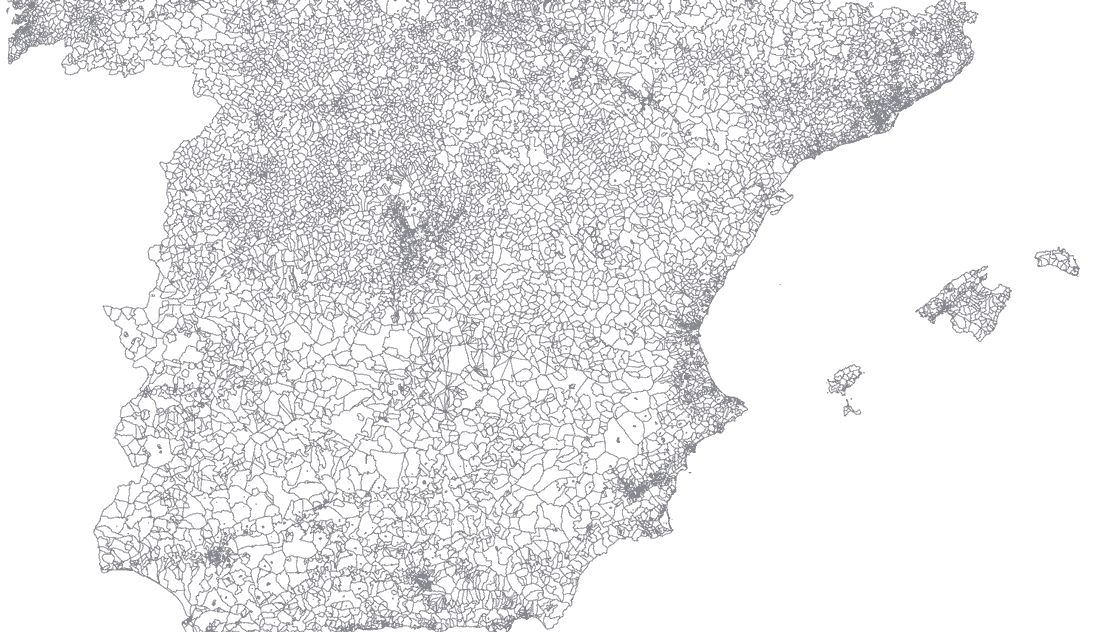
The goal is to select parts of a shapefile map and save it as another collection of .shp, .dbf, shx files. For example:
- select from Spanish census section:
- province: Madrid
- autonomy: Castilla y León, Galicia

Shapefile
The shapefile is a geospatial vector data format. Actually, it is a collection of three files:
- `.shp: binary shapes (polygon…), the geometry itself.
.dbf: data of shapes or records. In dBase format..shx: shape index format (not mandatory) for quicker indexing.
Other files like .proj, .shp.xml, .sbn … may be included.
Query snippet
The .dbf file has the following fields for each shape:
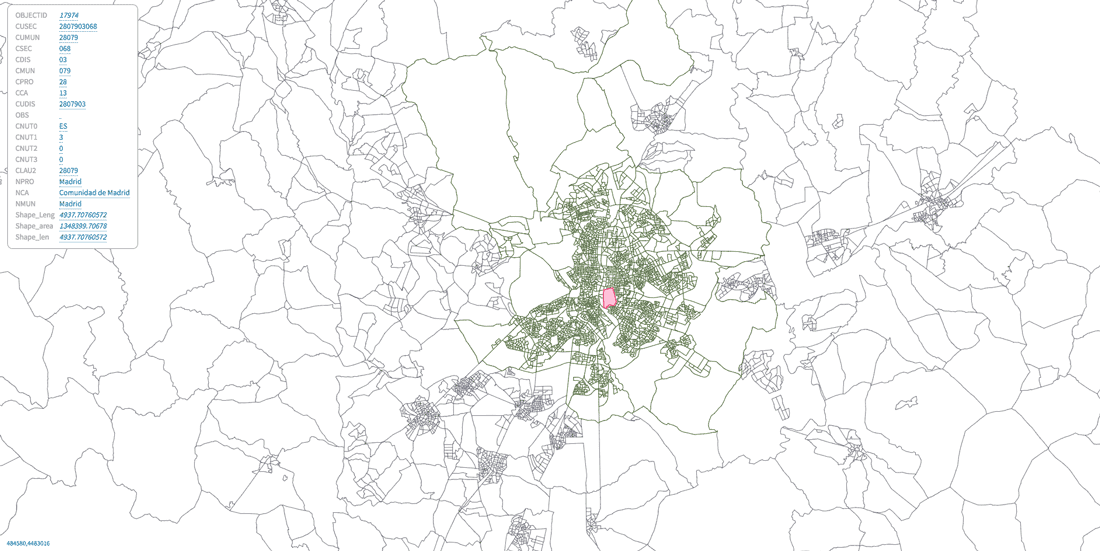
['OBJECTID', 'CUSEC', 'CUMUN', 'CSEC', 'CDIS', 'CMUN', 'CPRO', 'CCA', 'CUDIS', 'OBS', 'CNUT0', 'CNUT1', 'CNUT2', 'CNUT3', 'CLAU2', 'NPRO', 'NCA', 'NMUN', 'Shape_Leng', 'Shape_area', 'Shape_len']For example NPROV is the name of the province, NMUN is the name of the municipal area and CUMUN is the municipal code.
We would like to select in the same query, multiple fields with multiple values, for example, NPRO = Madrid, Sevilla and NMUN = Barcelona.
import shapefile
class ShapeFileUtils(shapefile.Reader):
''' Inherit from shapefile.Reader '''
def __init__(self, *args, **kwargs):
shapefile.Reader.__init__(self, *args, **kwargs)
# list of name fields
self.name_fields = [field[0] for field in
list(self.fields[1:])]
def query(self, **args):
'''
Makes a query on a shapefile.Reader object
:param args: list of fields and values to query
:return: the query shapefile.Writer object
'''
w = shapefile.Writer(shapeType=self.shapeType)
w.fields = self.fields[1:]
# shapefile 2.x version:
# w.encoding = self.encoding
for key, value in args.items():
index = self.name_fields.index(key)
for shaperec in self.iterShapeRecords():
if shaperec.record[index] in value:
w.record(*shaperec.record)
# shapefile 2.x version should use:
# w.shape(shaperec.shape)
# shapefile 1.x version should use:
w._shapes.append(shaperec.shape)
return wFirst we load the shapefile from the Spanish Statistical Institute into our brand new ShapeFileItils object that extends from shapefile.Reader class:
sf = ShapeFileUtils("SECC_CPV_E_20111101_01_R_INE",
encoding="latin1")Then we make a query selecting several provinces from the North of Spain, skipping Asturias, one autonomous region and the most populated municipalities from Asturias:
wq = sf.query(
NPRO=['Coruña, A', 'Ourense', 'Lugo', 'Pontevedra', 'Cantabria'],
NMUN=['Oviedo', 'Gijón', 'Avilés'],
NCA=['Castilla y León']
)
<shapefile.Writer object at 0x111278908>
wq.save('shapefiles/test/query_test')It will return a shapefile.Writer object that we can save and visualize in Mapshaper:

We can also make two queries to save two shapefiles and represent them together. Madrid province and Madrid municipality area:
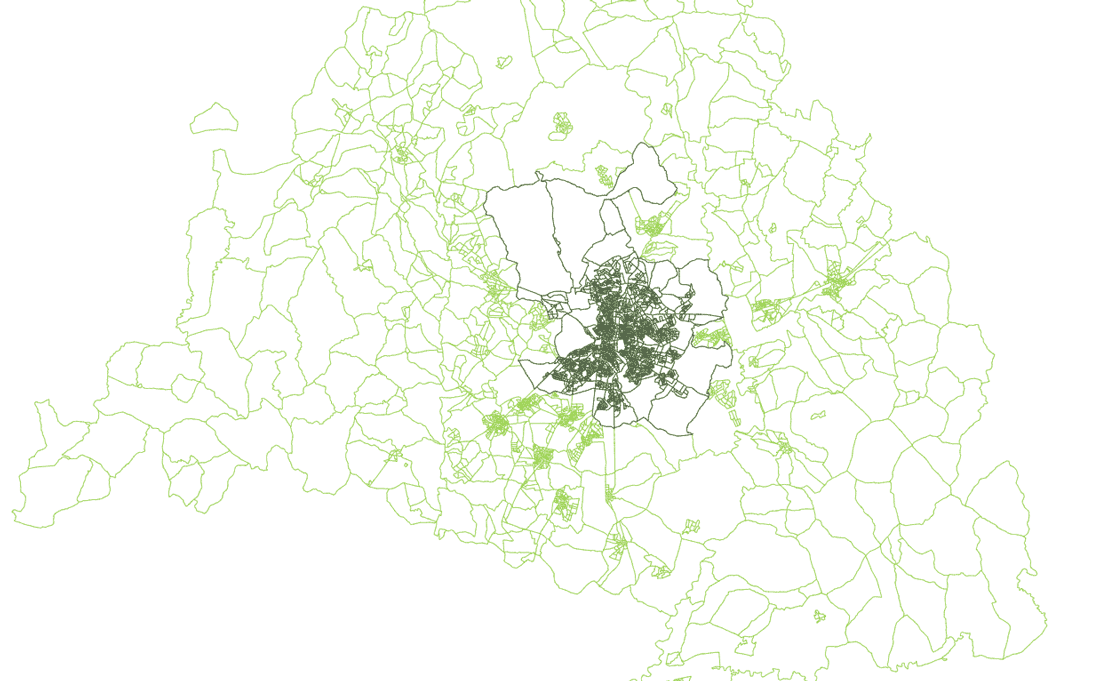
wq2 = sf.query(NPRO=['Madrid'])
wq3 = sf.query(NMUN=['Madrid'])View of Retiro census section inside Madrid municipality area inside Madrid Province:
Next steps
Making queries this way is kind of odd. It would be nice to make it similar to how Django ORM do it. For example:
sf.objects.filter( NPRO=’Barcelona’ ).exclude( NMUN=’Prat de Llobregat, El’ )…